Featured Projects

Airbnb New User Bookings: Classification
- Python, Sklearn, Matplotlib, Seaborn
- Algorithms: Random Forest, XGBoost
- Evaluation Metrics: NDCG (Normalized Discounted Cumulative Gain) score
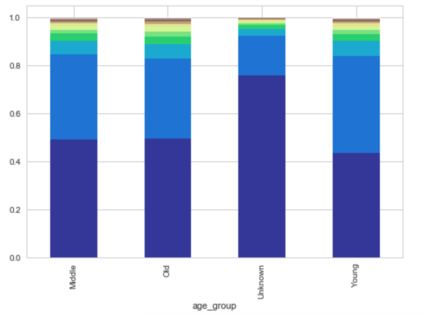
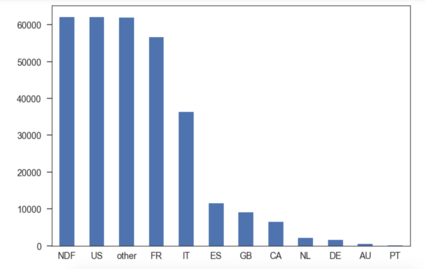
Predicts where the new user will book their first travel experience. Performed inferential statistics to analyze the relationship between various feature variables. Majority of the users prefer countries with different languages. Likewise, inferred 11 other observations. Evaluation metric NDCG (Normalized Discounted Cumulative Gain) is utilized for this project. Engineered new features and modeled random forest and XGBoost as multi-class ensemble learner. Using the ranking metrics to recommend the top 5 countries, as personalized content, for new users classification problem. Also, extracted essential features responsible for the prediction. The final visualization tells us that many of the new users will make their first booking in the US, France, and Italy. While NDF means No Destination Found, Airbnb says that if it is NDF, there wasn't any booking.
Check it out
Drug Re-purposing: Classification
- R, Python, S3, PySpark, Neo4j, CaretStack, R Shiny
- Algorithms: Logistic Regression
- Evaluation Metrics: High Recall, Low Precision
ML on Networks: Drug re-purposing can be an alternative approach to identifying new novel uses of existing FDA approved drugs. This project computes the prediction probability of whether a compound will cure a disease. Data is collected from 9 distinct sources and integrated into a network. It uses Neo4j to incorporate the data as a heterogeneous network. Network properties help in finding essential network links between each combination of drug and disease. Performed feature extraction on the network and modeled logistic regression classifier on the data to predict the probabilities for all the drug-disease pairs. Utilized S3 and Spark MLLib to achieve ML modeling. Predicted new compound indications. This project proposes to cut down the drug manufacturing costs by an estimate of 66.7%, through the drug re-purposing.
Check it out
Predicting flight delays based on Airport and Airline data: Regression
- Python, Flask_bootstrap, Sklearn, Seaborn, Bokeh
- Algorithms: SVM, Linear & Ridge Regression, Random Forest and Neural Networks
- Evaluation Metrics: MSE
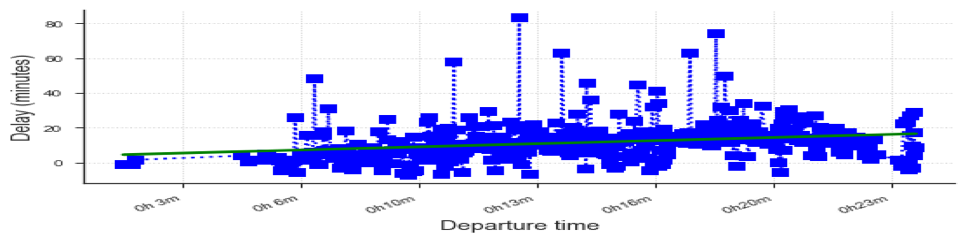
Predicts Flight departure delay for the origin airport and the airlines. Presented this real-world problem as a software application, which embeds machine learning algorithms. Flask allows the application software to take user input data from the website and push it to machine learning algorithm. Top 4 algorithms are Ridge Regression, Random Forest, Neural Net, and SVM. The final results will show the departure delays for an airline from a specific airport. Neural Net has performed the best by predicting the mean delay as 7.23 minutes for AA airline from DFW.
Check it out